如何彻底删除C盘下的windows.old文件夹
本文共 292 字,大约阅读时间需要 1 分钟。
本步骤不用任何第三方工具,即可将顽固的windows.old文件夹删除,操作有风险,诸君需谨慎!!!
- windows + R 键 打开运行窗口 输入
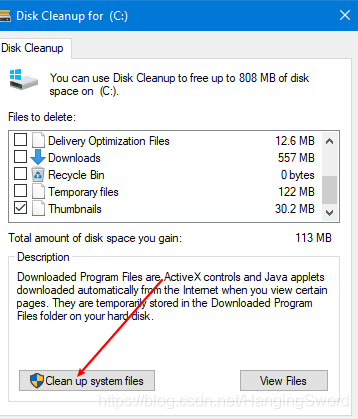
cleanmgr,出现下面的窗口后直接点击确定即可
- 接着点击下图中的“清理系统文件”,过一会儿会出现跟下图中差不多的选项
 3. 在要删除的列表中找到上个版本的Windows安装,向上滑动还有一个Windows更新的日志文件,这个可以选择删除,根据自己的需求勾选想要删除的内容后点击确定即可。
3. 在要删除的列表中找到上个版本的Windows安装,向上滑动还有一个Windows更新的日志文件,这个可以选择删除,根据自己的需求勾选想要删除的内容后点击确定即可。 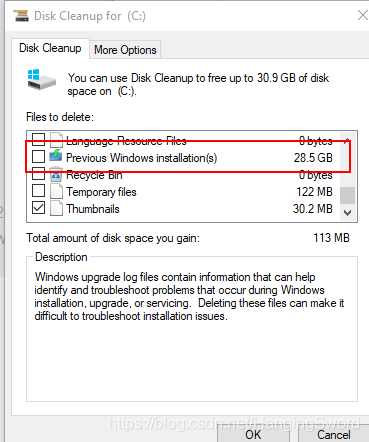 4. 等一会儿会出现一个警告,问你要不要继续,点击确定即可。
4. 等一会儿会出现一个警告,问你要不要继续,点击确定即可。
提示:将windows.old删除后,会存在无法还原到上个版本Windows的风险
转载地址:http://pmkj.baihongyu.com/
你可能感兴趣的文章
MSB与LSB
查看>>
MSCRM调用外部JS文件
查看>>
MSCRM调用外部JS文件
查看>>
MSEdgeDriver (Chromium) 不适用于版本 >= 79.0.313 (Canary)
查看>>
MsEdgeTTS开源项目使用教程
查看>>
msf
查看>>
MSSQL数据库查询优化(一)
查看>>
MSSQL数据库迁移到Oracle(二)
查看>>
MSSQL日期格式转换函数(使用CONVERT)
查看>>
MSTP多生成树协议(第二课)
查看>>
MSTP是什么?有哪些专有名词?
查看>>
Mstsc 远程桌面链接 And 网络映射
查看>>
Myeclipse常用快捷键
查看>>
MyEclipse更改项目名web发布名字不改问题
查看>>
MyEclipse用(JDBC)连接SQL出现的问题~
查看>>
mt-datetime-picker type="date" 时间格式 bug
查看>>
myeclipse的新建severlet不见解决方法
查看>>
MyEclipse设置当前行背景颜色、选中单词前景色、背景色
查看>>
Mtab书签导航程序 LinkStore/getIcon SQL注入漏洞复现
查看>>
myeclipse配置springmvc教程
查看>>